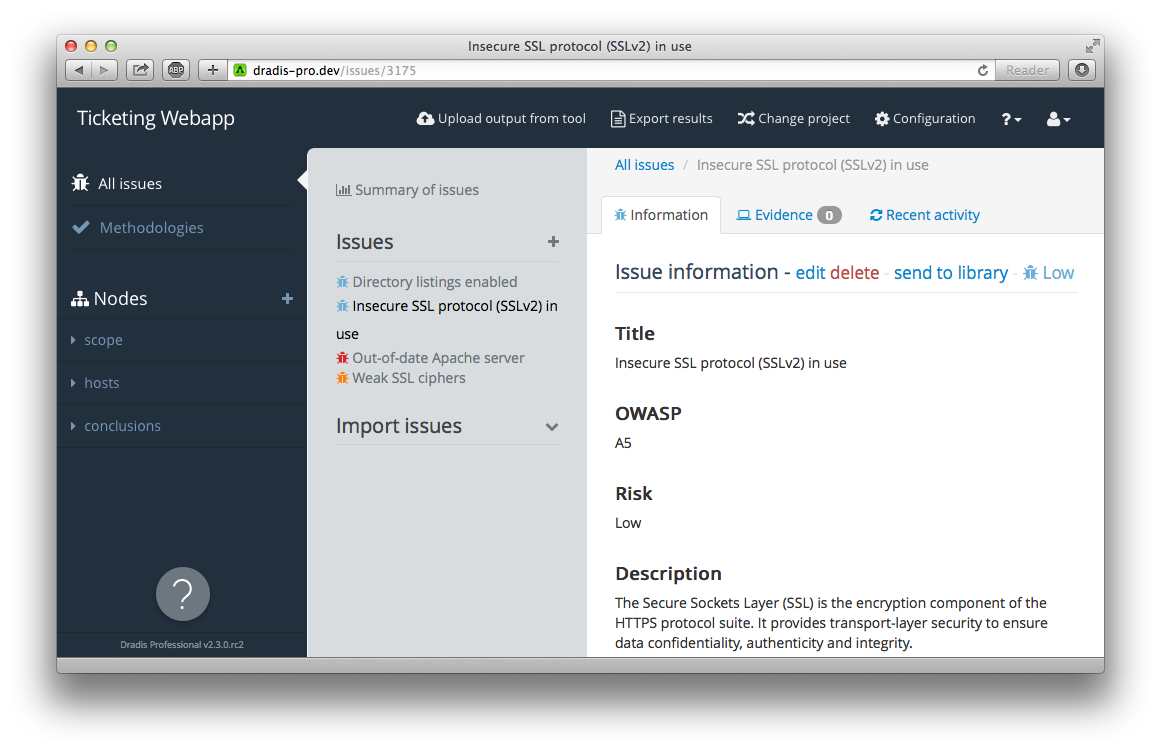
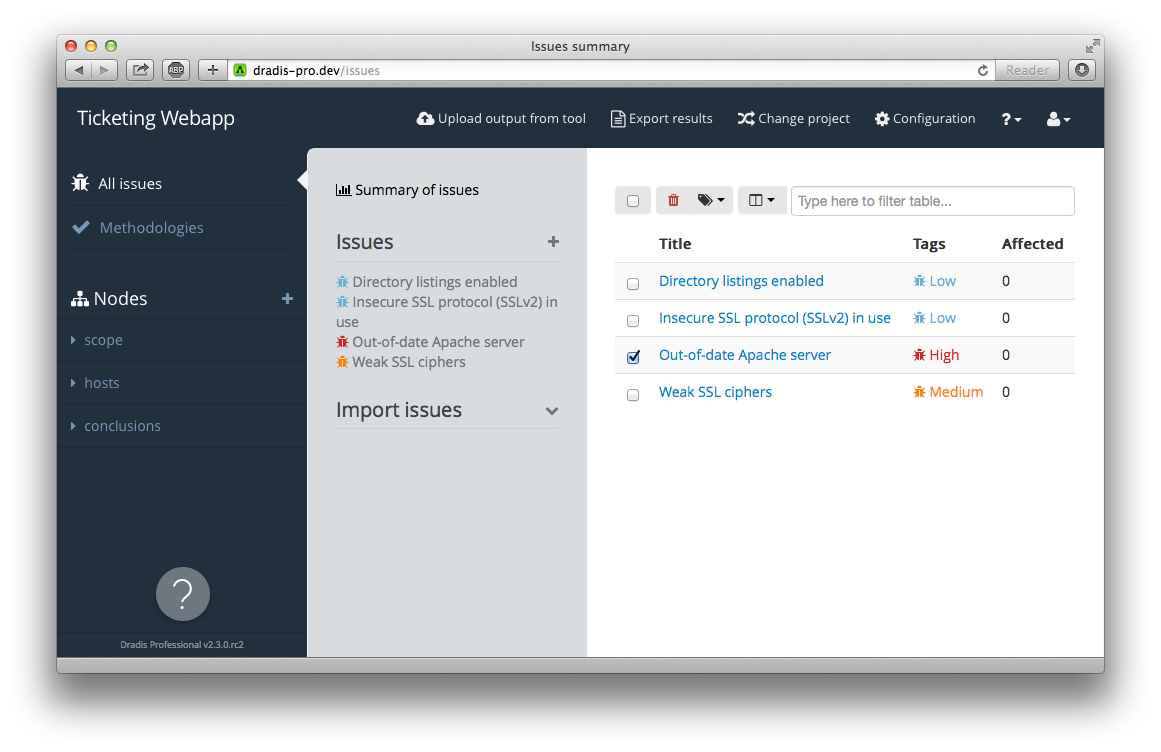
Dradis Professional Edition is a collaboration and automated reporting tool for information security teams that will help you create the same reports, in a fraction of the time.
This month we’re pleased to bring you Dradis Pro v2.4 with some long-requested improvements.
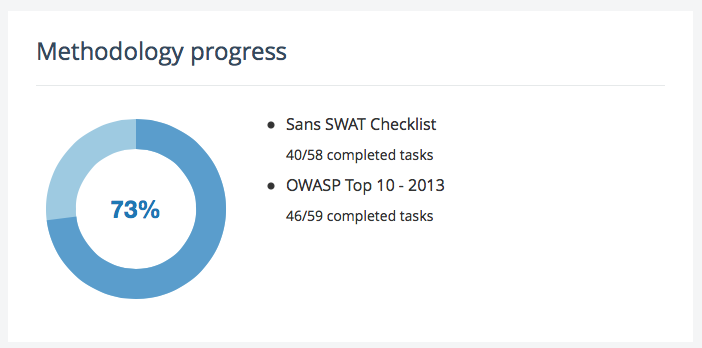
The highlights of Dradis Pro v2.4
- Project-wide search (see below)
- UI improvements (see below)
- I18n support for tags (thanks @kulisu)
- Validate on save
- Optimistic locking
- Evidence multi-add
- Copying of Report Template Properties
- Word reports
- Better file extension handling in Windows
- Minor bug fixing.
A quick video summary of what’s new in this release:
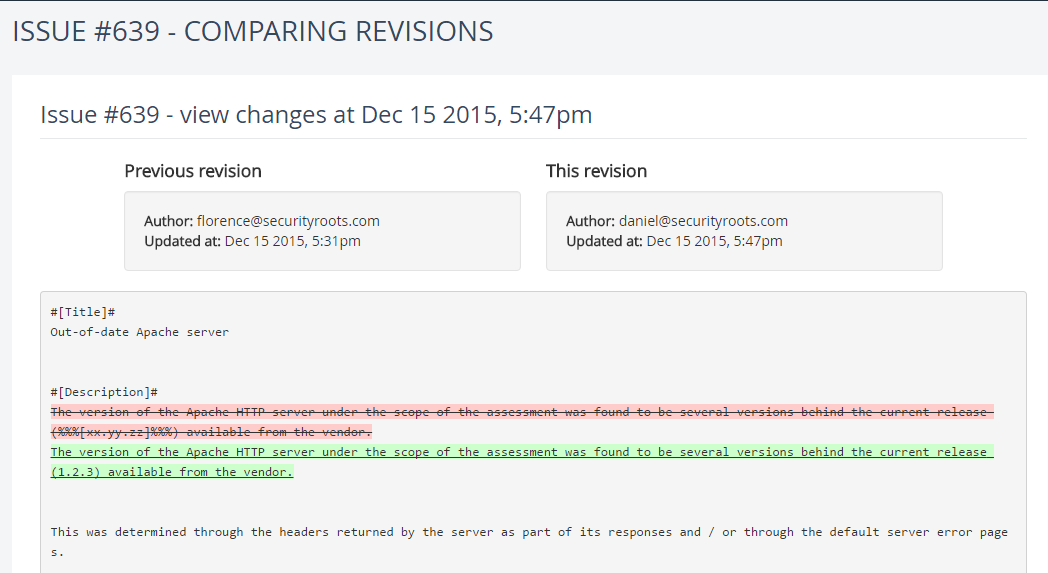
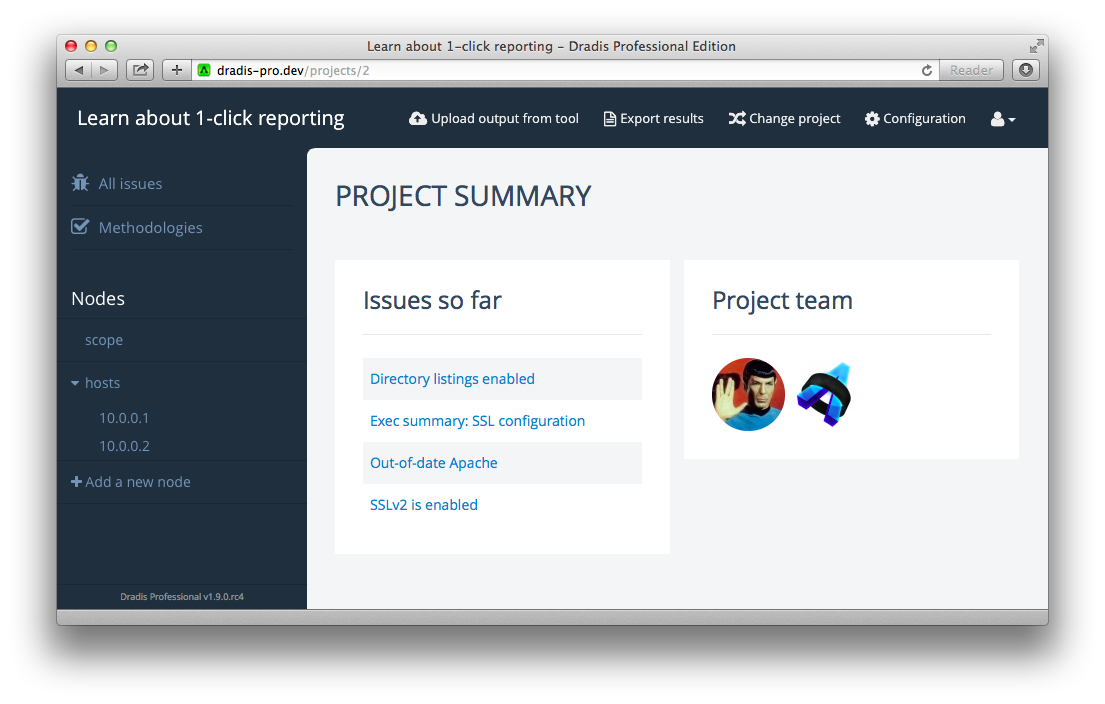
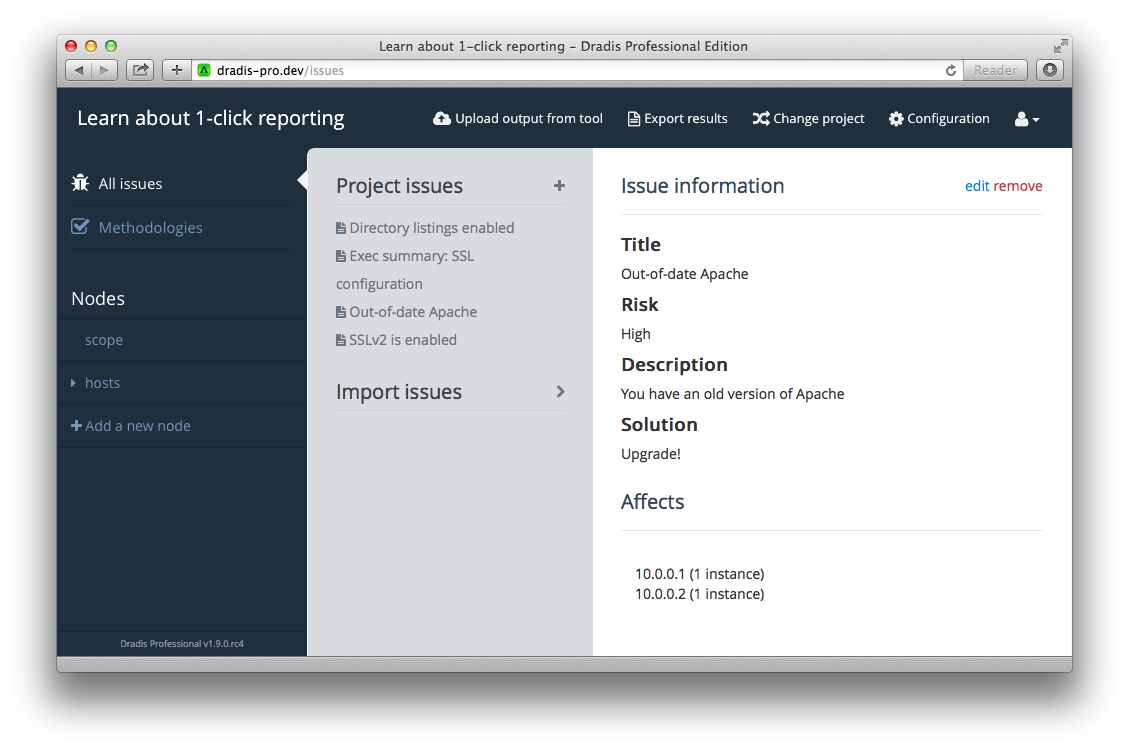
Project search
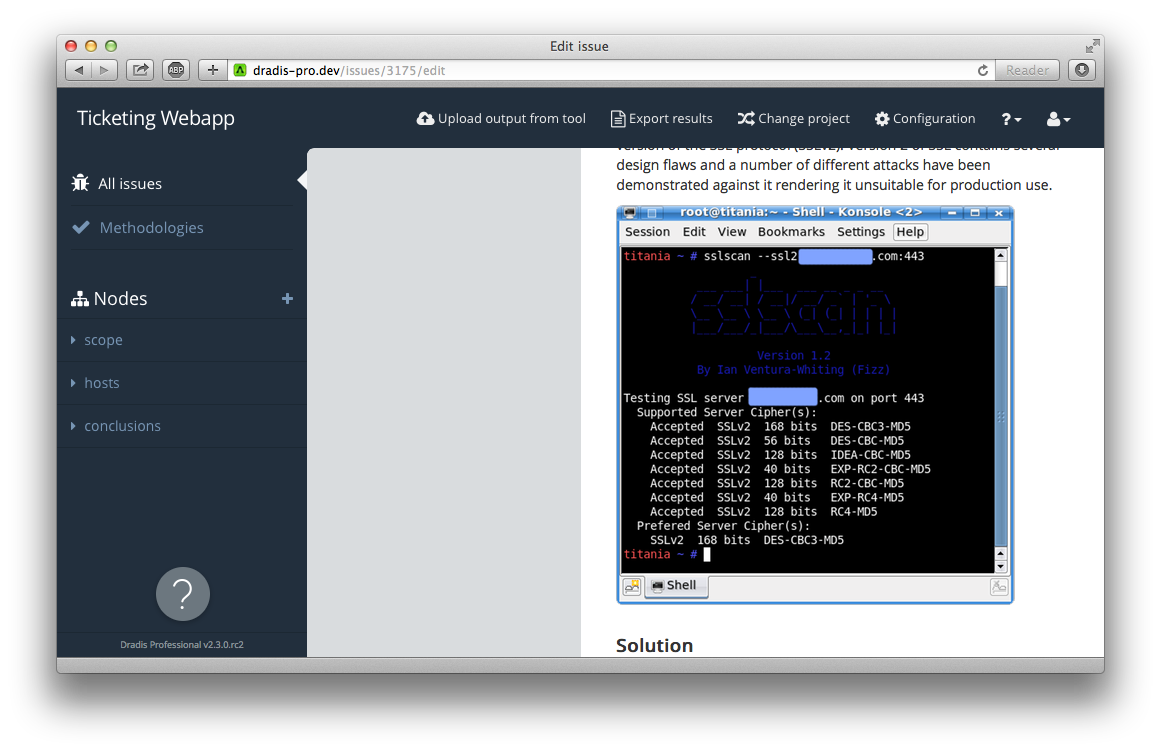
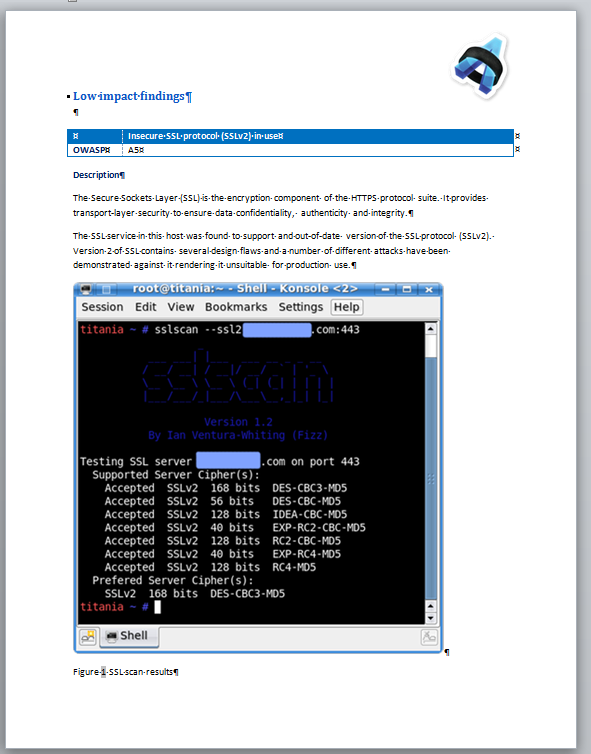
It is now possible to perform a project-wide full-text search against Evidence, Issues, Nodes and Notes:
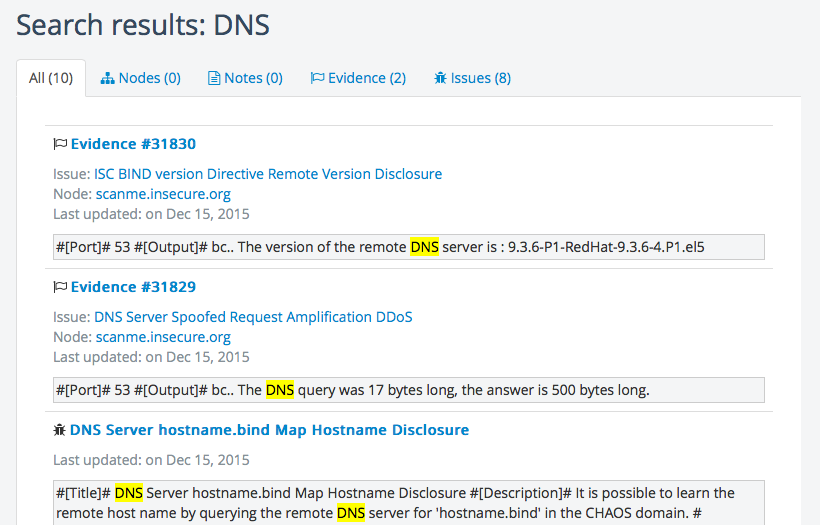

UI improvements
Dradis is used by over 270 teams in 33 countries around the world. When people are using your platform to edit and generate content in languages as varied as Simplified Chinese, Slovenian or Turkish, it becomes very easy to spot and squash internationalisation and character encoding bugs.
With this release we’ve made sure that Tags fully support names encoded in UTF-8:
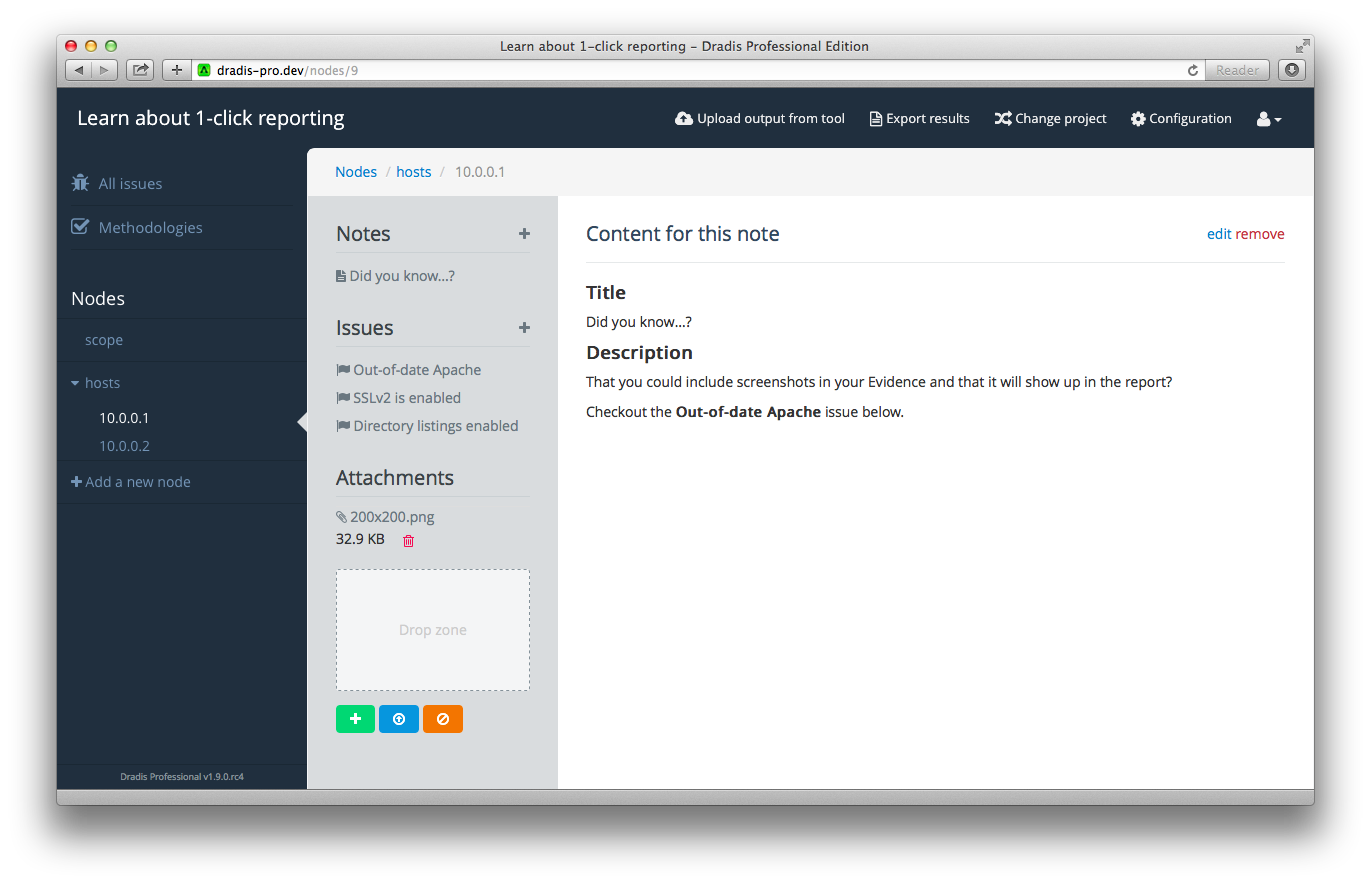
Evidence multi-add
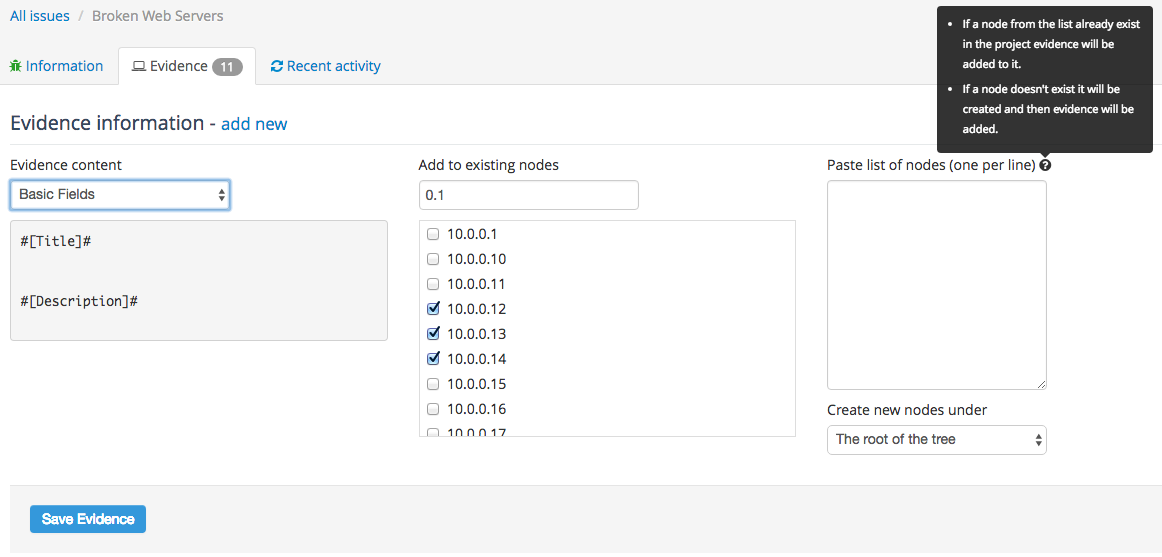
It is not uncommon to need to link the same Issue to a number of hosts in your project. We’ve redesigned the UI to make this task a lot simpler:
- Select the Evidence template you need (or start with a blank slate).
- Tick off the relevant items from the Existing Hosts list.
- If needed, paste list of new IP addresses that will be added to the project and also associated with your Issues.
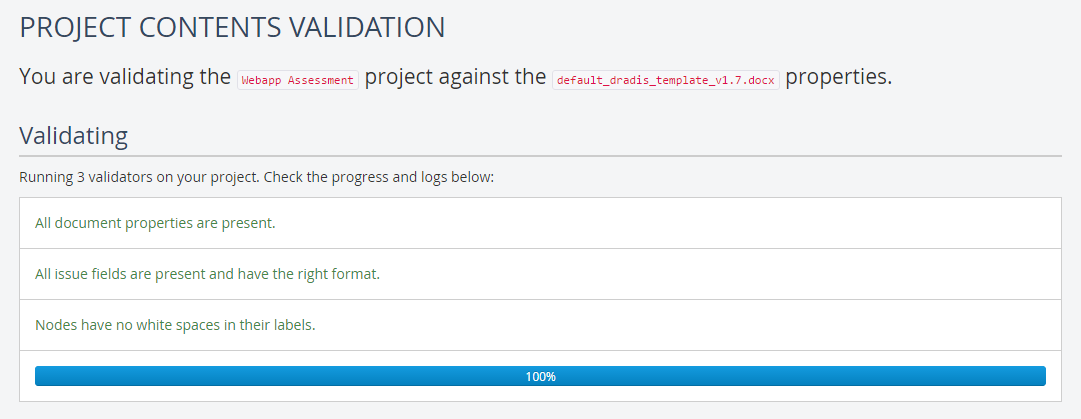
Validate on save
Teams working with Dradis normally need to use a number of different report templates (e.g. one for vulnerability assessments and one for social engineering). To make it easy for users to remember what information they need to provide on each template we’re now validating the contents supplied by the user against the individual template requirements so we can present a warning if the content doesn’t match the template’s expectations:

Optimistic locking
Have you ever been in a situation where just after updating an Issue or Note, you find out that one of your team mates was also editing that feature? From now on, Dradis will warn you when someone else has been modifying the content you were busy with, so you have the peace of mind to know you’re always working on the latest version of the content:

Still not using Dradis in your team?
These are some of the benefits you’re missing out:
- Automated reports, generate the same reports your clients know and love in a fraction of the time.
- Combine the output from 19+ different tools (including Qualys, Metasploit, Burp…) into a single report.
- Deliver consistent results. Never forget any steps. Always know what has been covered and what is still ahead.
- Everyone on the same page: all information available across the team.
- Dradis Professional is reliable, up-to-date and with comes with quality support
Read more about Dradis Pro’s time-saving features, what our users are saying, or if you want to start from the beginning, read the the 1-page summary.