We have discussed that the security report produced at the end of the engagement is a key component in proving your worth to your current and future clients.
When crafting a pentest report not only you’ll have to think about what to include in the report (sections, contents, tables, stats) but you will also need to decide how to write it. Let’s review what it takes to create a useful pentest report.
We are not talking about the specifics or the differences in structure between the deliverable produced for different project types (e.g. VA vs. wifi vs. external infrastructure). We want to provide you with the high-level guiding principles that you can use to ensure that the final security report you produce and deliver to your clients is a useful one.
The recommendations in this piece are based on dozens of report templates that we’ve seen as part of our report customisation service for Dradis Pro as well as our experience in the industry.
The goal of the engagement
The security report produced after each engagement should have a clear goal. In turn, this goal needs to be aligned with the client’s high-level goals. In “Choosing an independent penetration testing firm” we saw how identifying the goals and requirements of an engagement is a real pain point for some clients but also an opportunity for the security firm to provide education and guidance to strengthen the partnership with their customers.
A typical goal as stated by the client could be: “our objective is to secure the information”. This can be a good starting point albeit somewhat naive in all except the most simple cases. These days systems are so complex that assessing the full environment is sometimes not realistically possible (due to time on budget constraints). A more concrete goal such as “make sure that traveller A can’t modify the itinerary or get access to traveler B’s information” would normally produce a better outcome.
However, for the sake of this post, let’s keep it simple and focus on the broader goal of “securing the information”. With that in mind, the goal of the security report needs to be to communicate the results of the test and provide the client with actionable advice they can use to achieve that goal. That’s right, we need to persuade our clients to act upon the results we provide them.
In order to help your client to meet their goals, the more you know about them and their internal structures and processes the better. Who commissioned the engagement? Why? Is there a hidden agenda? Familiarising yourself with their industry and domain-specific problems will also help to focus your efforts on the right places.
Finally, it is important to know the audience of the deliverable you are producing. This seems like an obvious statement, but there is more to it than meets the eye. Who do you think is going to be reading the report your firm has produced? Is this going to be limited to the developers building the solution (or the IT team managing the servers)? Unlikely. At the very least the development manager or the project lead for the environment will want to review the results. Depending on the size of the company, this person may not be as technical as the guys getting their hands dirty building the system. And maybe this person’s boss or their boss’ boss will be involved. If your results expose a risk that is big enough for the organisation, the report can go up the ladder, to the CSO, CTO or CEO.
One security report, multiple audiences
At the very least it is clear that we could have multiple audiences with different technical profiles taking an interest in your report. If there is a chance that your deliverable will end up making the rounds internally (and the truth is that this is always a possibility), the wrong approach to take is to either produce a completely technical document full of nitty-gritty details or, going to the other end of the spectrum, delivering a high-level overview with the summary of the highlights of the test apt for consumption by C-level execs but lacking on technical depth.
The easiest way to find the middle ground and provide a useful document for both the technically inclined and also to the business types among your readers is to clearly split the document into sections. Make these sections as independent and self-contained as possible. I like to imagine that different people in the audience will open the document and delete the section they are not interested in and they will still get their money’s worth of value on what remains.
Problems you don’t want to deal with
Before delving into what to include and how to structure it, there are two problems you don’t want to deal with during the reporting phase of the project: collation and coverage.
Collation
It is still quite common that a sizable amount of the reporting time allocated during a test is spent collating results from different team members.
As we saw in the “Why being on the same page matters?” post, there are steps you can take to minimise the amount of collation work needed such as the use of a collaboration tool during the engagement.
Reporting time shouldn’t be collation time. All information must be available to the report writer before the reporting time begins. And it must be available in a format that can be directly used in the report. If your processes currently don’t make this possible, please consider reviewing them as the benefits of having all the information promptly available to the report writer definitely outweigh the drawbacks involved in updating those processes.
Coverage
How good was the coverage attained during the testing phase of the engagement? Was no stone left unturned? Do you have both evidence of the issues you uncovered and proof of the areas that were tested but were implemented securely and thus didn’t yield any findings? If not, the task of writing the final report is going to be a challenging one.
We have already discussed how using testing methodologies can improve your consistency and maximise your coverage raising the quality bar across your projects. Following a standard methodology will ensure that you’d have gathered all the evidence you need to provide a solid picture of your work in the final deliverable. Otherwise, the temptation of going down the rabbit hole, chasing a bug that may or may not be there may become too strong. We’ve all been there, and there is nothing wrong with it, as long as it doesn’t consume too much time and enough time is left to cover all the areas of the assignment. If you fail to balance your efforts across the attack surface, this will be reflected in the report (i.e. you won’t be able to discuss the areas you didn’t cover) and it will reflect badly on your and your firms’ ability to meet your client’s expectations.
Security report sections
For the rest of this post, we will assume that you have been using a collaboration tool and are following a testing methodology during the testing phase and as a result, you’ve got all the results you need and have attained full coverage of the items under the scope of the engagement.
The goal of this post is not to provide a blow-by-blow breakdown of all the possible sections and structure you need to provide, there are some comprehensive resources on the net that go beyond what we could accomplish here (see Reporting – PTES or Writing a Penetration Testing Report). We want to focus on the overall structure and the reasons behind it as well as the approach and philosophy to follow when crafting the report to ensure you are producing a useful deliverable. At a very high level, the report content must be split between:
- Executive summary
- Technical details
- Appendices
Executive summary
This is the most important section of the report and it is important not to kid ourselves into thinking otherwise. The project was commissioned not because an inherent desire to produce a technically secure environment but because there was a business need driving it. Call it risk management or strategy or marketing, it doesn’t matter. The business decided that a security review was necessary and our duty is to provide the business with a valuable summary.
The exec summary is probably the section that will be read by every single person going through the report, it is important to keep that in mind and to make sure that it is worded in a language that doesn’t require a lot of technical expertise to understand. Avoid talking about specific vulnerabilities (e.g. don’t mention cross-site request forgery) and focus on the impact these vulnerabilities have on the environment or its users. The fact that they are vulnerable to X is meaningless unless you also answer the question “so what?” and explain why they should care, why it is a bad thing and why they should be looking into mitigating the issue. As Guila says in the article, why give a presentation at all if you are not attempting to change the audience’s behaviors or attitudes?. And the security report is most definitely a presentation of your results to your client.
Don’t settle for just throwing in a bunch of low-end issues to the conclusions (e.g. “HTTPs content cached” or “ICMP timestamps enabled”) just to show that you uncovered something. If the environment was relatively secure and only low-impact findings were identified, just say so, your client will appreciate it.
Frame the discussion around the integrity, confidentiality, and availability of data stored, processed and transmitted by the application. Just covering the combination of these 6 concepts should give you more than enough content to create a decent summary (protip: meet the McCumber cube).
Apart from the project’s conclusions and recommendations, it is important that this section contains information about the scope of the test and that it highlights any caveats that arose during the engagement. Again this is to correctly frame the discussion and give the readers that may not be as familiar with the particular environment (e.g. CSO) the appropriate context.
In addition, it offers you protection should the client decide to challenge your results, approach or coverage attained. If a host or a given type of attack was requested by the client to be out of scope, this needs to be clearly stated. Along the same lines, if there were important issues affecting the delivery (e.g. the environment was offline for 12 hours) these have to be reflected. There is no need to go overboard on this either, if the application was offline for half an hour on the first day out of a five-day test and you don’t think this had an impact (e.g. you were able to do something else during that time or managed to attain full coverage throughout the rest of the test), there is no point in reflecting it on the report.
Technical details
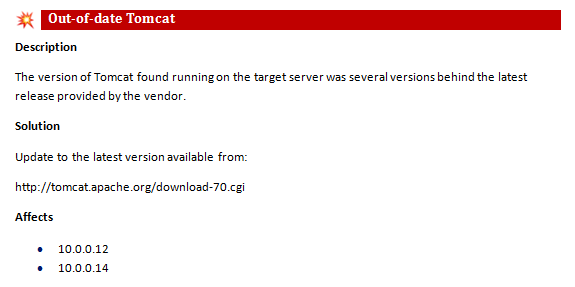
This is the area that should be easier to craft from the tester’s perspective. There is not much to add here other than trying to keep your entries relevant to the current project. For instance, don’t include any MSDN references explaining how to do X in .NET when the application is written in Java. Or don’t link to the Apache site if all servers are using IIS.
I don’t want to get into the scoring system for the vulnerabilities because that could add a few thousand words to the post, just pick a system that works for you and your clients and try to be consistent. This is where having a report entry management system in place (*cough*, like VulnDB) can help maintain consistency of language and rating across projects and clients, especially for larger teams.
A final note on what to include on each finding: think about the re-test. If six months down the line, the client comes back and requests a re-test, would any of your colleagues be able to reproduce your findings using exclusively the information you have provided in the report? You may be on holiday or otherwise unavailable during the re-test. Have you provided enough information in the first place? Non-obvious things that usually trip you over are details about the user role you were logged in as when you found the issue or remembering to include the series of steps you followed from the login form to the POST request that exposed the issue. Certain issues will only be triggered if the right combination of events and steps is performed. Documenting the last step in the process doesn’t usually provide a solid enough base for a re-test.
Finally, remember that the purpose of the document is not to show how smart you are or how many SQLi techniques you used. Everything needs to be weighed and measured against the engagement goals and the business impact to the client. For instance, an unglamourous absence of account lockouts in the client’s public facing webapp is likely to have a bigger impact for their business and users than a technically brilliant hack that combined path traversal, command execution and SQLi in backend admin interface only reachable by IT administrators over a secure VPN link.
Appendices
The Appendices should contain the information that while not key to understand the results of the assessment would be useful for someone trying to gain a better insight into the process followed and the results obtained.
An often overlooked property of the Appendixes section is that it provides a window to the internal processes followed by the testing team in particular and the security firm in general. Putting a bit of effort into structuring this section and providing a more transparent view of those processes would help to increase the transparency of your operations and thus the trust your clients can place on you. The more you let them see what is going on behind the curtain the more they’ll be able to trust you, your team and your judgment.
In the majority of the cases, this additional or supporting information is limited to scan results or a hodgepodge of tool output. This is fine as it will help during the mitigation and re-test phases but there are other useful pieces of information that can be included. For instance, a breakdown of the methodology used by the team is something that you don’t see that often. I’m not talking about a boilerplate methodology blob (i.e. ‘this is what we normally do on infrastructure assessments’), but a real breakdown of the different areas assessed during this particular engagement along with the evidence gathered for each task in the list to either provide assurance about its security or reveal a flaw. This will show that your firm is not only able to talk the talk during the sales and pre-engagement phases but that your team, on a project-by-project basis, are walking the walk and following all the steps in the methodology. Providing your clients with this level of assurance is going to automatically set you ahead of the pack because not a lot of firms are capable (or willing) to do so.
tl; dr;
Understanding the project goals, realising that the security report you are crafting will have multiple audiences of different technical expertise, making sure that the deliverable reflects not only the issues uncovered but also documents the coverage attained and the process involved in doing so will go a long way towards producing a useful pentest deliverable. Couple that with enough technical information to provide the project team with sufficient knowledge on the issues uncovered, the best mitigations to apply and a means to verify their reviewed implementation and you will have succeeded in your role of trusted security advisor.